Then Twitch pulled the plug on Sings and I started doing my regular Friday night folk streams. At first this involved running OBS and Logic Pro on my aging MacBook Pro and it was sort of okay, until I started having guests and doing Song Swaps – the MacBook simply wasn’t up to the job of running Logic, OBS and Zoom, so for a while I had some unholy lashup, with Zoom and OBS running on the PC, my Mac running Logic, with patch leads between the Mac and PC audio interfaces so I could hear my guests and vice versa. It wasn’t pretty.
What saved it was adding an ATEM Mini Pro ISO from BlackMagic. Now I could hand off all the capturing, streaming and recording duties to that box and run Logic and Zoom on the Mac and everything just worked (with an utter rats nest of cables on my desk). The ATEM takes HDMI input from up to four sources and lets me switch what gets sent to the stream between them. There’s also a monitor preview output that can be switched independently between those four sources, as well as multiview and stream previews. Of course, I quickly used up all four sources, and I don’t even have a second camera! The way things are arranged by default is that I have a camera feed, my mac’s primary and secondary displays, and the output from a Raspberry Pi. Mac screen 2 is where the zoom window lives, and is connected to the ATEM via an HDMI splitter with the second output feeding a 7-inch field monitor that sits on a teleprompter setup so I can look guests in the eye.
The primary Mac screen is where I set up streams and drive Logic from. It feeds into the ATEM mostly so I can see it in the preview window or full size when I need to without having to have a another screen, but if I ever get a second camera, I’ll break mac screen 1 out to its own monitor and dedicate input 2 to that secondary camera. Input 4 is a Raspberry Pi that I use for motion graphics. This used to be a copy of chromium running in kiosk mode to display the Ko-Fi stream widget which displays donations as they happen, but I’ve recently managed to compile OBS studio with a working browser plugin and I’m using that instead now, which should allow me to add more overlays later. The only catch with that is that I’ve not yet managed to get Companion to compile, so I think I’ll have to move that onto the Mac.
This all worked fine until recently. You see, the thing I love about unaccompanied singing is singing harmonies. And harmonies don’t work unless the timing is properly tight. That means I can’t sing harmonies with Zoom guests because the speed of light screws things up completely. I got around this by harmonising with myself – either by using a Looper plugin in Logic1 or just by using Logic’s multi-tracking2 to record multiple layers of a song’s chorus. It all works, and works well, but I could never work out how to record harmonies for shanty type refrains.
Consider:
Oh the rain it rains all day long
Bold Reilly oh, bold Reilly!
And them Northern winds they blow so strong
Bold Reilly oh’s gone away
Chorus:
Goodbye my sweetheart, goodbye my dear-o
Bold Reilly oh, bold Reilly
Goodbye my darling, goodbye my dear-oh
Bold Reilly oh’s gone away
Ideally, I want to be layering up harmonies on the Bold Reilly oh, bold Reilly! and Bold Reilly oh’s gone away lines within each verse, as well as on the chorus (and potentially on any chorus repeats too). It should be possible to set up Logic’s live looping feature to enable this sort of thing, but I could never work out how, and I wasn’t ready to switch to Ableton Live (where I couldn’t be sure I knew how to make it work either). So I stuck to just harmonising on the chorus and wishing there was a better way.
Enter Loopy Pro!
I’ll write a full review of Loopy Pro one of these days, but suffice it to say, there is now a better way. Loopy Pro is the long awaited successor to Loopy HD, a software looper for iOS. It’s been a very long time coming, but by god, does it deliver! As well as being a looper, it’s a great replacement for MainStage and (at least for live use) Logic Pro, and it runs on even pretty ancient iPhones and iPads. It’s predecessor was remarkably capable, but was ‘just’ a looper with a configurable number of loops available. Loopy Pro is fully customisable, supporting any number of loops, one shot samples, beat slicing, AUv3 hosting, mix busses, control widgets, faders and dials. There’s a deep system of actions and ‘follow actions’ that allow you to customize its behaviour as well as its appearance, and the audio routing capabilities could embarrass some far more expensive DAW software. It’s astonishingly capable.
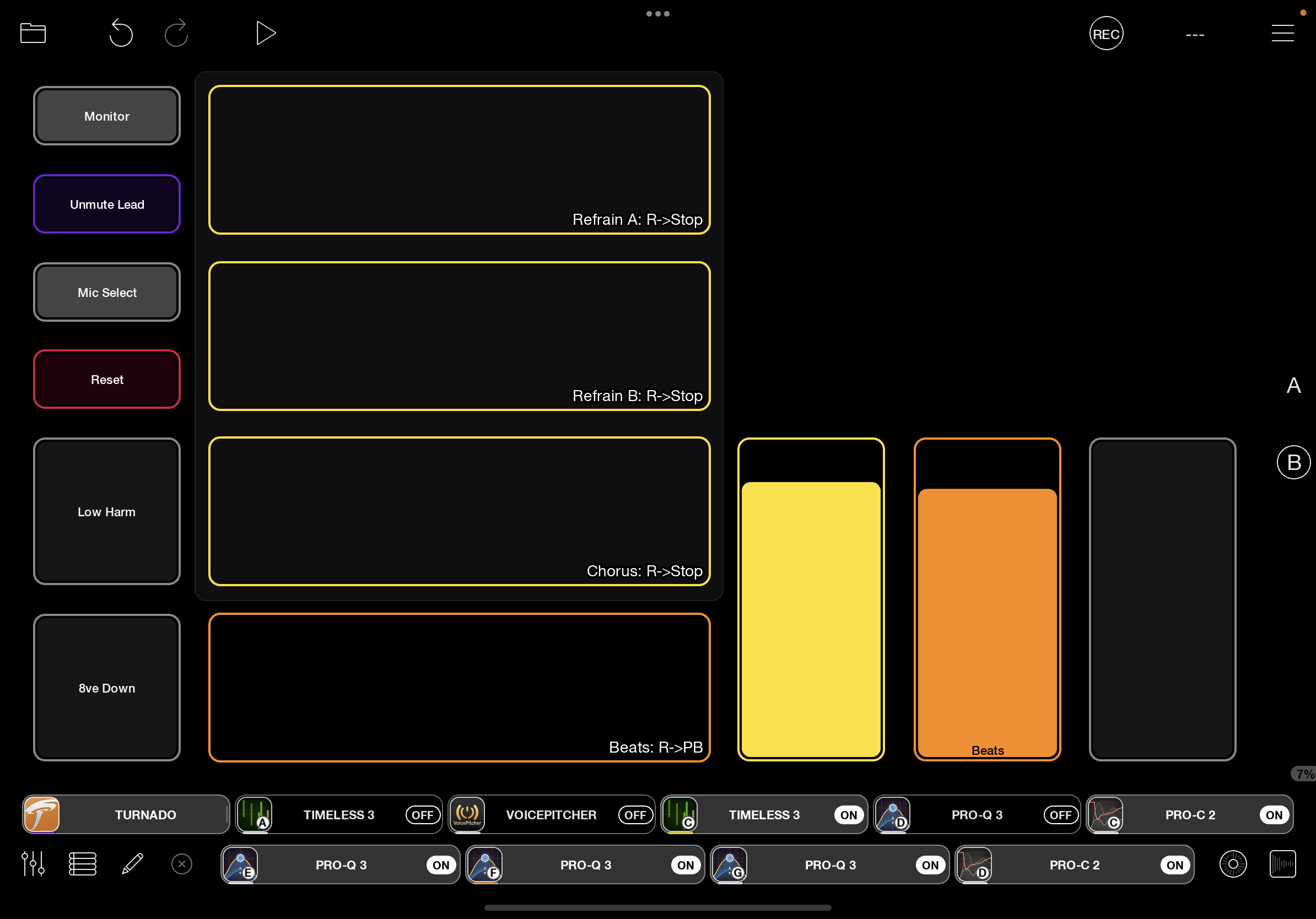
Figure 1: Loopy Pro configured for singing ‘shanty’ structured chorus songs
I’ve been fiddling with it since it was released, and now have it set up to allow me to sing shanty style songs with harmonies on the refrain as well as stuff like this:
so now I’m running Friday night stream audio from the iPad, leaving the Mac to run Zoom. This has all been made much easier since I added a new audio interface: the iConnectivity AUDIO4c interface is a remarkable bit of kit. Uniquely, as far as I can tell, it can be used as an audio interface simultaneously by my mac and my iPad, and can route audio from the iPad to the mac and vice versa. It’s got four inputs and six outputs, which is two more than existing interface. That means I can have my guest and me fed to the ATEM mini on separate channels, as well as giving myself a different headphone mix. And it’s only one rack unit high!
The remaining bit of the puzzle is to reliably capture the iPad display. I’m looking for, and so far failing to find, a powered USB-C hub that has a bulletproof iPad HDMI connection and gigabit ethernet, which is much more reliable when it comes to remote control of the ATEM. It’s a frustrating search. Everything I’ve found so far has intermittent HDMI dropouts, which would be annoying enough if it weren’t for another ‘feature’ of iOS and iPadOS.
It works like this: on iDevices, you don’t have the option to choose which audio interface you want to use, instead the OS autoselects whichever interface was plugged in most recently. Which would be fine (sort of) if it weren’t for the fact that an HDMI connection to an audio capable device is treated as a new audio interface. So… if the HDMI connection was reliable, getting prepped for a stream would just involve unplugging the audio interface from the hub, connecting the HDMI and reconnecting to the AUDIO4c. But then the HDMI drops and comes back, and suddenly it is the most recently connected interface and the stream’s audio is buggered.
If you know of an iPad friendly USB-C hub that has rock solid HDMI, then I’d love to hear about it because my search is getting really frustrating. Right now I’m working around it by disconnecting the audio, screen sharing to the Mac and reconnecting the audio, but even with a dual screen mac set up, screen sharing takes over both screens and the whole thing has a bunch of latency that you don’t really want – it’s surprising how little latency will start making audio software in particular seem seriously out of sync. I can correct for that when editing, but not so much on a live stream.
But… once I have reliable HDMI from the iPad I run into another problem. Where do I plug it in? Suddenly four inputs on the ATEM aren’t really enough.
Time to start saving up for an ATEM Mini Extreme ISO, which is the extra-wide version of the ATEM Mini Pro ISO, complete with 8 HDMI inputs, 2 HDMI outputs, 2 USB-C connections, a 3.5mm audio jack output (so I can monitor the audio going to the stream rather than just looking at the VU meters on the multiview display) and something called a ‘Super Source’, which would definitely simplify the business of setting up the split screen view when I have a Zoom guest.
The extreme version appears to fix pretty much everything that I find slightly annoying about the Mini, which is brilliant, but could be brillianter. Ah well, a boy can dream.
If you’re interested in seeing what all this technology ends up looking like on stream, then I stream at 8pm UK time every Friday night on my YouTube channel. Maybe pop by, and if you like what you see and hear, don’t forget to like and subscribe.
-
I used the delightfully named Augustus Loop from Expert Sleepers combined with a Lua script I wrote to make it behave more or less the way I wanted it to. Kind of fiddly to set up, but repaid the effort. There’s still a few things that AL can do that I can’t do with Loopy Pro, but as I write those are due in the next big Loopy patch. ↩︎
-
Logic isn’t really set up to do live sound, but MainStage, which is, can’t do multi track recording and playback and I couldn’t work out how to configure its looper to emulate that. So I just used Logic. ↩︎
Will I ever learn to leave well enough alone? I've written up the state of my streaming setup here.